
티스토리 뷰
퍼옴: http://www.popit.kr/kubernetes-introduction/
Intro
이 글에서는 Kubernetes 가 무엇인지 설명하고, 아키텍쳐와 구성요소에 대해 살펴봅니다. 그리고 minikube 를 이용해 로컬에서 Kubernetes 를 사용해 보겠습니다. 목차는 아래와 같습니다.
- What is Kubernetes?
- Kubernetes Architecture (abbreviated)
- Getting Started with minikube
- Kubernetes Object: Pod
- Kubernetes Object: Service
- Kubernetes Object: Deployment
- Kubernetes Object: Pet Set
- Kubernetes Object: Others
- Summary
- Furthermore
- References
Caution
- 작성자는 최대한 정확한 내용을 기록하려 했으나 글에 오류가 있을 수 있습니다. 또한 Production 적용을 위해서는 더 많은 자료를 참고 부탁드립니다
- 이하의 내용은 docker, docker-compose, docker-swarm 등에 대해 이해하고 있다는 가정 하에 쓰여졌습니다. 잘 모르신다면 Docker Self-Paced Online Learning 을 보고 오시면 더욱 쉽게 이해할 수 있습니다.
- 이 글에서는 kubernetes 의 구성요소, 인터널 등을 간략히 다룹니다. Autopilot Pattern 등의 볼륨 매니지먼트 기술을 찾아 오셨다면 아래의 글 참고 부탁드립니다.
What is Kubernetes?
kubernetes (이하 k8s) 는 docker-swarm, marathon 과 같은 container orchestration 툴입니다. docker-swarm#production demo 영상에서는 docker-swarm 을 이용해 1000개 노드에 50000 개의 컨테이너를 띄우는 것을 보여줍니다. (영상을 보시길 추천드립니다.)
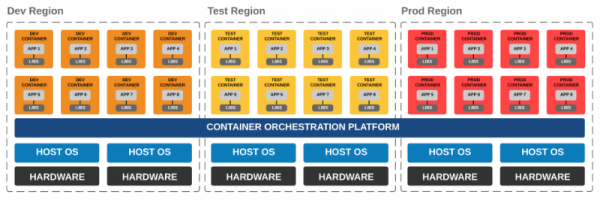
host 머신 한대라면 docker run 이나 docker-compose 등 무엇으로 container 를 실행해도 상관 없습니다. 그러나 사용자가 많아지면 하나의 host 에서 모든 container 를 실행할 수 없습니다. (host 에서 fail 이라도 발생하면..) 그러나 여러대의 host 에서 container 를 실행하려면 inter-host container 네트워킹과, host machine 의 리소스를 고려한 container 분배 등을 고려해야 합니다. 이런 문제들을 해결해주는 것이 바로 container orchestration 툴입니다. 요즘은 여러 container orchestration 툴을 골라 쓸 수 있게 해주는 rancher 와 같은 플랫폼도 나오고 있습니다.
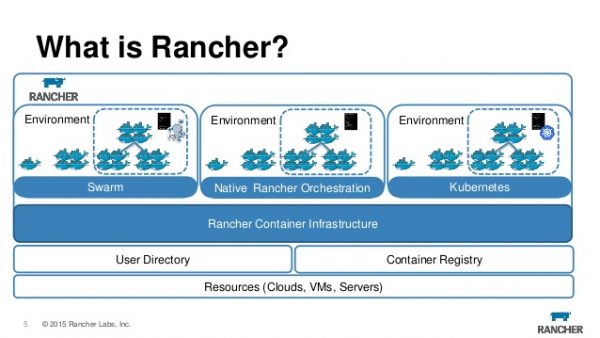
kubernetes 가 하는 일은
- 여러 host (= node in k8s) 를 묶어 클러스터를 구성하고
- container 를 적절한 위치에 배포하고 (auto-placement)
- container 가 죽으면 자동으로 복구하며 (auto-restart)
- 필요에 따라 container 를 매끄럽게 추가(scaling), 복제(replication), 업데이트(rolling update), 롤백(rollback) 할 수 있습니다
- 이 외에도 수 많은 기능이 있으며, What is k8s? 에서 확인할 수 있습니다
kubernetes 를 사용하기 위해서는 아래의 내용들을 이해해야 합니다. 이 글에서는 object 와 internal 에 대해서만 간략히 설명합니다. 필요한 내용은 kubernetes docs 를 통해 얻을 수 있는데, 다행히도 문서가 장황하지 않습니다. 필요한 내용을 필요한 만큼만 설명하고 있기 때문에 날 잡아서 쭈욱 읽기에도 괜찮습니다.
- kubernetes object (e.g pod, pet set, service, selector 등)
- kubernetes internal
- multi-host 위에서 container 실행시 고려해야 할 것들
- service discovery
- networking
- volume management
- log aggregation 등
Kubernetes Architecture (abbreviated)
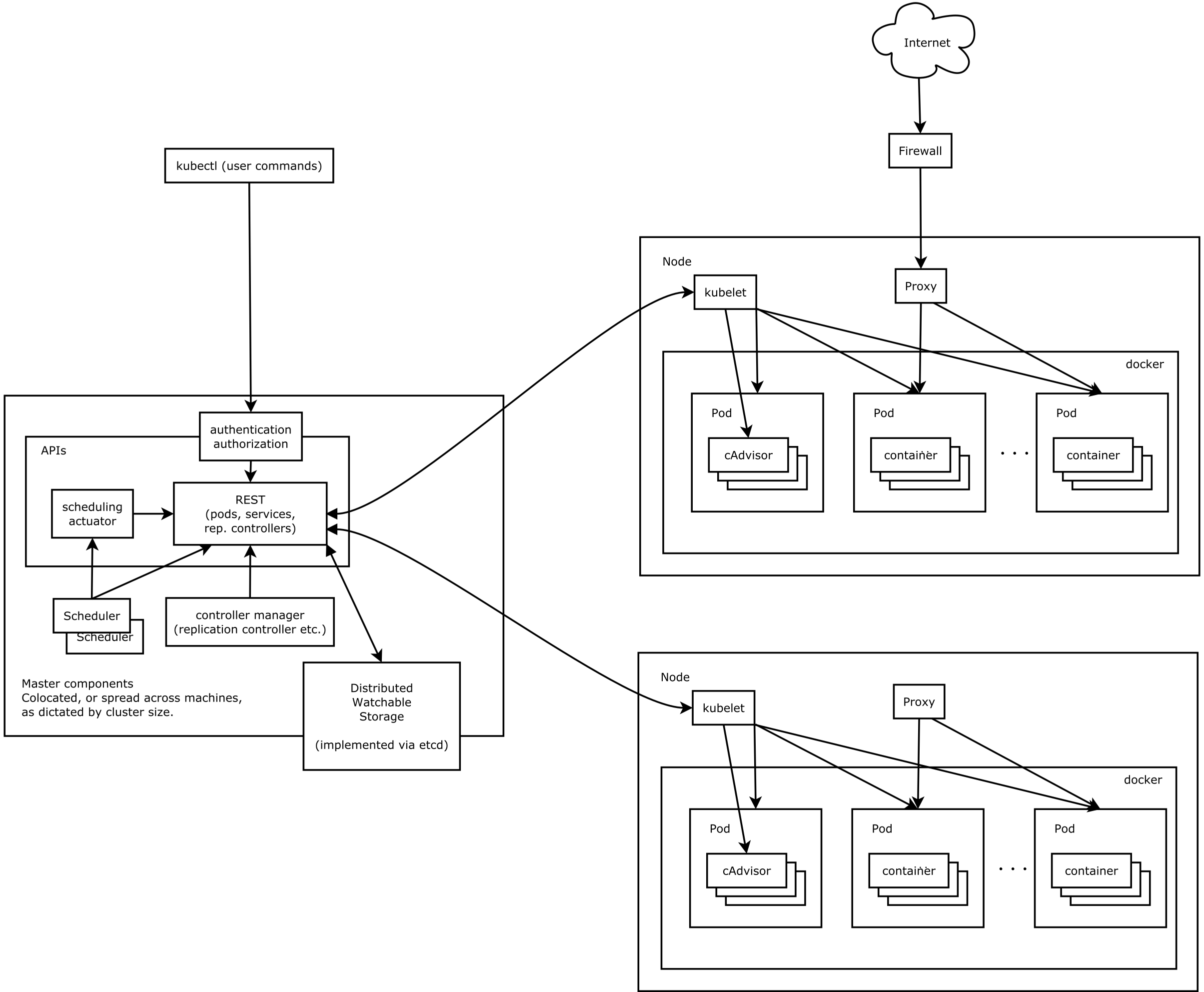
시작 전에 간단히 구성 요소를 짚고 넘어가겠습니다.
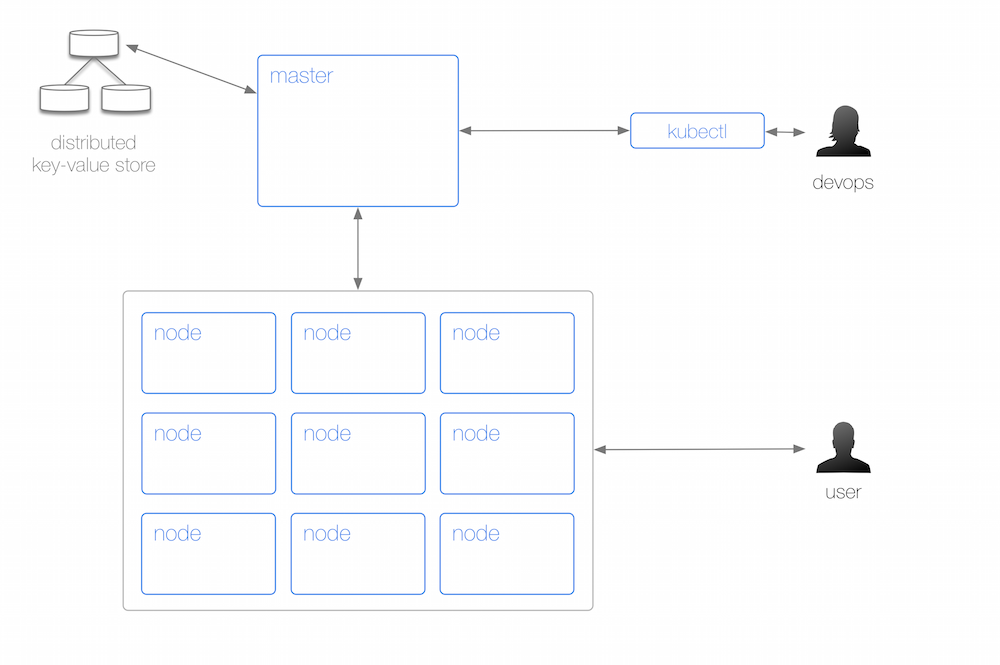
하나의 k8s 클러스터는 하나의 master 와 여러개의 node 로 구성되어 있습니다. 개발자는 kubectl 을 이용해서 master 에 명령을 내리고, node 를 관리하는 반면 사용자 (endpoint user) 는 node 에 접속해 서비스를 이용합니다. 위 그림을 조금 더 자세히 보겠습니다.
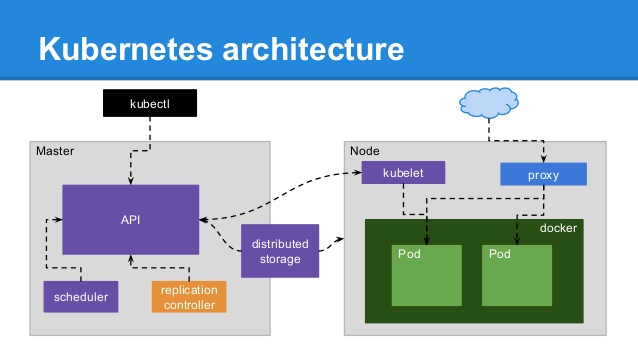
- master 에는 (현재는 master 가 단일 노드이지만 추후 multi-node master 가 지원될 예정)
- 작업을 위한 api server
- state 를 관리하기 위한 분산 저장소 (default 는 etcd)
- scheduler
- controller manager 등이 있습니다.
- node (= minion) 에는
- master 와 통신하는 kubelet (agent, 현재는 containerized 되어있지 않음) 이 있고
- 외부의 요청을 처리하는 kube-proxy
- container 리소스 모니터링을 위한 cAdviser 등이 있습니다.
이제 다시 큰 그림을 자세히 보면 다음과 같습니다.
Getting Started with minikube
minikube 를 설치하면 로컬에서 kubernetes 를 실행해볼 수 있습니다. 진행하기 전에 GCE 에 가입하신 후 Kubernetes: Hello World Walkthrough 를 진행하고 오시면 내용을 이해하시는데 더욱 도움이 됩니다.
추가적으로 kubectl 1.3.0+ 의 경우에는 bash 와 zsh completion 이 들어있습니다. 이걸 이용하면 편합니다. 만약 gcloud 이용해서 kubectl 를 설치하셨다면 1.2.5 버전이 깔릴 수 있습니다. 이때는 kubectl install 참고하시어 설치하면 됩니다.
Kubernetes Object: Pod
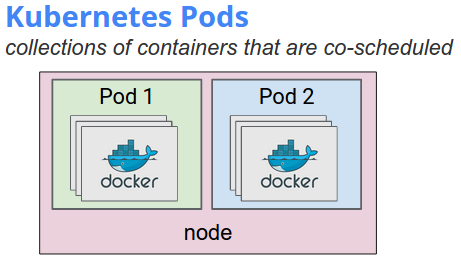
하나 또는 여러개의 container 묶음을 pod 이라 부릅니다. docker 에서 container 끼리 통신하려면 같은 network 위에 있도록 구성해야 하는 반면 (compose 도 동일), 하나의 pod 내에 있는 contianer 끼리는 그럴 필요가 없습니다. (pod 의 종료, 삭제 관련해서는 Termination of Pods 를 참고)
- 같은 IP 와 port space 를 가지기 때문에 localhost 로 통신이 가능하며
- volume 을 공유합니다
- 만약 어느 container 가 죽고 재시작되어도 pod 이 살아있는 한 shared volume 은 유지됩니다.
In terms of Docker constructs, a pod is modelled as a group of Docker containers with shared namespaces and shared volumes. PID namespace sharing is not yet implemented in Docker.
위에서 k8s 가 auto-restart 등을 해준다고 했었는데 테스트 해보겠습니다. 그 전에 먼저 클러스터가 정상적으로 세팅이 되었는지 확인해 보겠습니다. 저는 minikube 를 이용해서 로컬에서 실행했으므로 아래와 같은 결과가 나옵니다. kubectl 을 여러 클러스터 중 하나에 붙어서 커맨드를 날릴 수 있도록 도와주는 docker-machine 정도로 이해하시면 됩니다. (단위가 다르지만)
이제 아래와 같이 nginx.yaml 을 만들겠습니다.
만들어진 replication controller 를 k8s 에 올려보면,
pod 하나를 죽여보겠습니다. 재생성되는걸 확인할 수 있습니다.
Kubernetes Object: Service
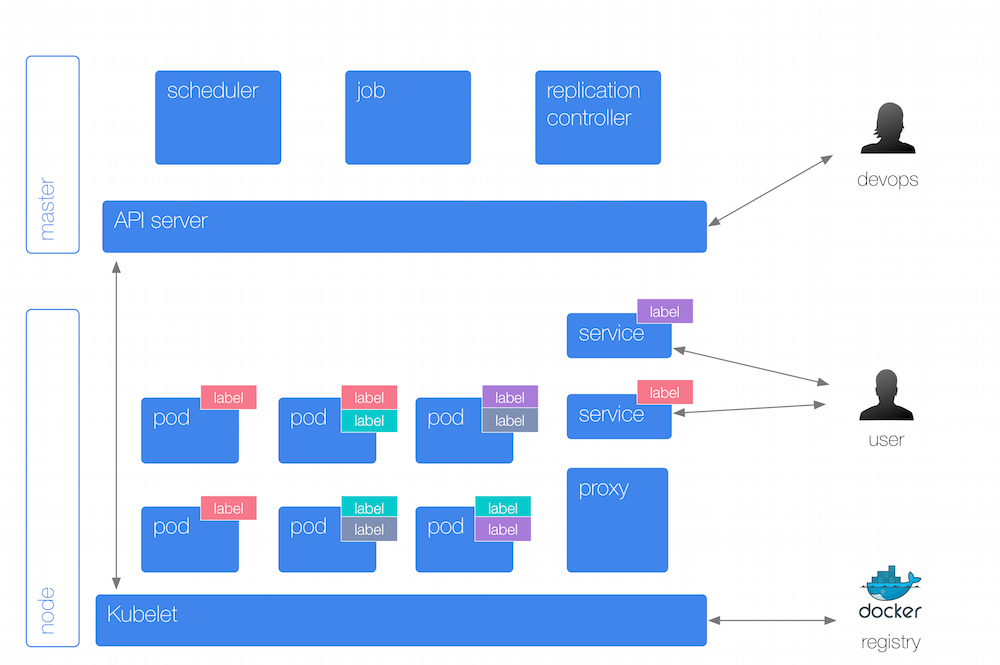
pod 은 생성/삭제 될 수 있습니다. replication-controller 를 이용하면 심지어 동적으로도 scale up/down 이 가능한데 이럴 경우 IP 가 변경/추가/제거 되므로 k8s 에서는 external pods 이나 pods pods 간의 안정적인 통신을 위해 service 라는 object 를 도입했습니다.
Services provide a single, stable name and address for a set of pods. They act as basic load balancers.
위 그림을 잘 보면, pod 에 있는 label 과 동일한 컬러의 것이 service 에도 있고 해당 service 가 같은 label 컬러를 가진 pod 을 위한 것임을 쉽게 알 수 있습니다.
위에서 생성한 nginx pods 를 위한 service 를 nginx-svc.yaml 이란 이름으로 만들어 보겠습니다. selector 를 잘 보세요.
이제 생성하면, nginx-svc service 의 EXTERNAL-IP 가 <nodes> 로 보입니다. 전체 node 에 대해서 외부 포트를 열어서 그렇습니다. NodePort 대신 LoadBalancer (cloud provider 가 지원할 경우만 사용가능) 타입을 이용하거나 ingress 를 이용할 수 있습니다.
As of Kubernetes v1.0, Services are a “layer 3” (TCP/UDP over IP) construct. In Kubernetes v1.1 the Ingress API was added (beta) to represent “layer 7” (HTTP) services.
192.168.64.2:31968 을 접근해보면, nginx 가 떠있음을 확인할 수 있습니다. pod 이 생성될때 active service 에 대해서 kubelet 이 service 의 IP, port 와 관련된 환경변수를 pod 에 주입합니다. (service 가 먼저 생성되어 있어야 함) 예를 들어 service name 이 redis-master 라면 다음과 같은 값들이 주입됩니다.
하여 pod 간 통신에는 env variable 을 이용할 수 있으나, DNS 를 이용하는 것이 더 권장됩니다. 그리고 label 값은 kubernetes/example/guestbook 처럼 붙이는 것이 권장됩니다.
Kubernetes Object: Deployment
deployment 는 Kubernetes: Hello World Walkthrough 를 진행하셨다면 감이 오셨을수도 있겠습니다. rolling update, rollback 등을 지원하는 pod, replica set 입니다.
위와 같이 nginx-deployment.yaml 을 만들고, 배포하면
정상적으로 배포되었는지는 rollout status 커맨드를 이용해서 확인할 수 있습니다. 이제 container 의 nginx 버전을 올려보겠습니다.
모든 pod 을 한번에 생성하고, 한번에 오래된 pod 을 죽이는 방식으로 일어나는 것이 아니라 rolling update 처럼 하나하나씩 진행됩니다.
Deployment can ensure that only a certain number of Pods may be down while they are being updated. By default, it ensures that at least 1 less than the desired number of Pods are up (1 max unavailable).
Deployment can also ensure that only a certain number of Pods may be created above the desired number of Pods. By default, it ensures that at most 1 more than the desired number of Pods are up (1 max surge).
보면 replica set 은 2개지만 nginx-deployment-1159050644 은 업데이트 전 버전인 1.7.9 pod 이 하나도 없고 (desired = 0), nginx-deployment-671724942 만 3 개의 pod 을 가지고 있습니다. 이전 replica set 을 유지하는 이유는 rollback 을 위해서 인데요
여기서 CHANGE-CAUSE 가 none 인 이유는 deployment 커맨드에서 –record 옵션을 사용하지 않아서 그렇습니다. revision 값을 지정해 살펴보면
이제 rollback 해 보겠습니다.
이전 pod 이 죽고, 새로운 pod 이 생성되는 과정을 볼 수 있습니다.
Kubernetes Object: Pet Set
stateless application 의 경우에는 기존의 pod, replica set 등을 이용해 쉽게 배포하고 확장할 수 있었지만 cluster 로 동작하는 경우에는 각 instance 간 networking 을 위해 reliable name (e.g index based, advertised hostname) 등의 기능이 필요했습니다. pet set 은 stateful (e.g clustering) applications 의 지원을 위해 1.3 버전에서 alpha 기능으로 추가되었습니다. (CHANGELOG#1.3)
1000 Instances of Cassandra using Kubernetes Pet Set 에서는 alpha 기능인 pet set 을 이용해 1000 개의 카산드라 인스턴스를 배포하고 sample job 을 돌린 경험을 공유하고 있습니다.
We deployed 1,000 pets. Technically with the Cassandra setup, we could have lost 333 nodes without service or data loss
8,072 Cores The master used 24, minion nodes used the rest
100,510 GB persistent disk used by the Minions and the Master
380,020 GB SSD disk persistent disk. 20 GB for the master and 340 GB per Cassandra Pet.
팀 내에서 20+ broker 로 kafka cluster 를 운영하고 있는데다가 container 기반 기술에 관심이 많아 적용을 해보고 싶긴 한데 아직 레퍼런스가 없어 안타깝습니다. github issue 를 보면 example 을 만들기 위해 논의는 진행중인것 같습니다.
- kubernetes #5017: Example: Kafka/Zookeeper
- SO: Kafka on k8s multi node
- Running a ZK and kafka clusters on k8s
- Github: kubernetes-kafka
Github: kubernetes-contrib/pets 를 보시면 pet set 을 이용해 cluster 를 구성하는 샘플이 몇개 있습니다. 현재까지는 mysql, redis, ZK 정도가 있네요. Github: kubernetes/examples 도 다양한 샘플이 있으므로 한번 쭈욱 둘러보시면 도움이 될듯 합니다.
Kubernetes Object: Others
위에서는 pod 과 volume 의 life cycle 이 동일하다고 했지만, 사실 꼭 그렇지는 않습니다. 다양한 type 의 volume 이 지원되기 때문인데요 emptyDir 이외의 volume type 을 이용하면 pod 이 죽더라도 데이터를 유지할 수 있습니다. (e.g gcePersistentDisk, flocker) persistent volume (PV) 는 일종의 networked storage 로 pod lifecycle 을 벗어나 존재할수 있으면서도 사용자가 리소스의 양을 특정지어 요청할 수 있는 volume 입니다.
Managing storage is a distinct problem from managing compute. The PersistentVolume subsystem provides an API for users and administrators that abstracts details of how storage is provided from how it is consumed
- Daemon Set 은 node 마다 추가되야 하는 프로세스가 있을때 사용할 수 있습니다.
running a cluster storage daemon, such as glusterd, ceph, on each node
running a logs collection daemon on every node, such as fluentd or logstash
- Job 은 배치 작업처럼 실행후 종료되는 Job 을 의미합니다.
나머지 오브젝트는 Reference 의 Glossary 를 참조하시면 확인할 수 있습니다.
Summary
k8s 를 살펴보며 느낀점을 요약하면 다음과 같습니다.
- docker 1.12 기준으로 docker-swarm: built-in orchestration 이 대폭 개선되었음에도 불구하고, k8s 가 더 많은 기능과 자세한 세팅을 제공합니다. 실제 production 적용시에 다양한 요구사항이 생길 수 밖에 없기 때문에 k8s 의 다양한 기능은 큰 장점으로 보입니다.
- GCE 를 쓰지 않아도 됩니다. AWS 에서 사용할 수 있으며, AWS 의AWSElasticBlockStore, ELB, SSL 등 많은 기능들을 직접 지원하기도 합니다. AWS 위에서 kubernetes 를 돌리고 싶다면 다음의 문서를 참조해보시는 것도 좋겠습니다. (@Jaehoon Jay Choi 님의 코멘트)
- ingress 등의 기능과 Future Work 등을 보고 있노라면 정말 다양한 기능을 빠르게 추가하려고 노력한다는 느낌을 받습니다.
Furthermore
- Log Aggregation 은 아래의 내용을 참고하실 수 있습니다.
- k8s cluster 간 연결은 k8s cluster federation 이라 불립니다.
- k8s production 적용을 위한 guide 도 있습니다. (Working with Containers in Production)
- CI 관련해서는 Circle CI 가 싼 가격에, 연동 잘되고 기능 많습니다. 아래와 같이 build (scala) 세팅하면 google container registry 에 push 하고 gcloud 커맨드 까지 직접 내릴 수 있으니 develop branch 정도라면 k8s deployment 이용해서 바로 롤링 업그레이드 가능합니다. (만약 SBT 가 느리다면 courseir 나 circle CI build cache 등을 이용해보세요.)
References
- Image: Post Title
- What is Kubernetes?
- k8s.info
- SO: How to expose a Kubernetes service externally using NodePort
- Image: Kubernetes Pod
- Kubernetes Architecture Slide1
- Kubernetes Architecture Slide2
- 1000 Instances of Cassandra using Kubernetes Pet Set
- Kubernetes Design Docs: Architecture
- Docker Swarm Demo
- How Linux Containers Shatter Traditional SDLC Approaches
- Rancher Slideshare
'CI > Docker' 카테고리의 다른 글
| Docker 네트워크 구성과 설정 (0) | 2017.04.05 |
|---|
- Java
- 모두의딥러닝
- ML
- spark
- web
- NIO
- 머신러닝
- 파이썬
- javascript
- mysql
- 중앙정보처리학원
- API
- mybatis
- BigData
- tensorflow
- Docker
- AI
- 점프투파이썬
- serverless
- python
- spring
- Error
- AWS
- memory
- TDD
- Configuration
- Maven
- 텐서플로우
- executor
- Gradle
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |