
티스토리 뷰
출처: https://blog.lael.be/post/917
기술이 매우 빠르게 발전한다.
배워도 배워도 계속 배워야 한다.
최근에 라엘이가 앞으로 100년동안은 나타나지 않을 것이라고 예상했던,
4 Byte UTF-8 문자열을 보고 여러 깨닳은 바가 있었고
여러분에게 도움이 될만한 정보가 있어 공유하려고 한다.
데이터베이스를 구축하다보면 텍스트 데이터(Text Data)를 취급해야 할 때가 있다.
이때 반드시 고민해야 하는 것이 있는데, 바로 문자셋(character set)을 선택하는 것이다.
핵심 단어의 뜻
먼저 중요한 두 단어 Charset 과 Collation 의 뜻에 대해서 알고 가자.
구글 번역기를 이용하여 단어 자체의 뜻을 알아보자.
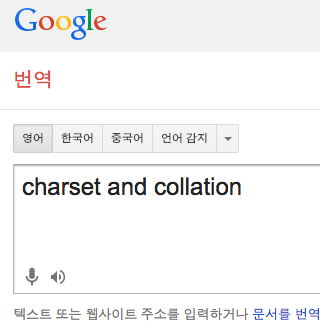
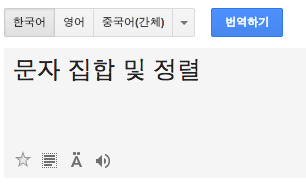
charset 은 문자 집합, collation 은 정렬을 뜻한다.
자료형이 왜 필요하나?
먼저 자료형이 왜 필요할지부터 생각해보자.
컴퓨터 프로그램은 프로그래머가 의도한 대로 동작한다.
이 때 같은 목적의 프로그램이라고 할지라도 효율적으로 동작하는 것이 더 좋은 프로그램이 된다.
“컴퓨터 알고리즘(Computer Algorithm)” 학문에서는 이를 평가(Performance Analysis)하기 위해서,
“시간복잡도(time complexity)“와 “공간복잡도(space complexity)“의 개념을 사용한다.
(참고로 이것을 평가하는 대회가 [ACM-ICPC;International Collegiate Programming Contest;대학생알고리즘대회] 이다.
라엘이도 두번정도 참가해보았으며 컴퓨터 알고리즘의 중요성을 알 수 있게 된다. 관련글 : https://blog.lael.be/post/136 )
같은 이유로 데이터베이스 학문도
“더 작은 공간을 사용하면서”
“더 빠르게 처리할수 있는”
방향으로 발전되었고 해당 목적을 위해서 데이터 자료형을 사용하게 되었다.
예를 들어 어떤 프로그램에서 사용자의 선택여부를 저장하고자 할때
1) boolean 자료형의 true/false
2) int 자료형의 0, 1
3) char 자료형의 0,1
모두 같은 동작을 하는데 boolean 으로 저장하는 것이, 제일 작은 공간을 사용하고, 제일 빠르다.
UTF-8 이란?
실생활의 대부분의 데이터는 텍스트기반(text-centric)이다.
당연히 실생활의 모든 텍스트 데이터를 저장할 수 있는 자료형이 필요로 하게 되었다.
이것을 위해서 나온 charset이 UTF-8 이다.
UTF-8 문자 집합은 1~4 바이트까지 저장이 가능하게 설계되었다. (가변 바이트)
관련 자세한 자료는 라엘이가 쓴 글인 https://blog.lael.be/post/77 을 참고하기 바란다.
MySQL/MariaDB 에서도 UTF-8 을 지원한다.
이때! 간과한 사실이 있는데, 전세계 모든 언어가 21bit (3바이트가 조금 안됨)에 저장되기 때문에
MYSQL 에서 utf8 을 3바이트 가변 자료형으로 설계하였다.
그렇기 때문에 최근에 나온 4바이트 문자열(Emoji 같은것)을 utf8 에 저장하면 값이 손실되는 현상이 발생한다!
기존에 널리 사용되던 MySQL 구축(설계)에서 환경이, charset 은 utf8 , collation 은 utf8_general_ci 인데 이러한 대부분의 환경에서 문제를 일으키는 것이다.
4바이트 UTF-8 문자열
MySQL에서 부랴부랴 원래의 설계대로 가변-4바이트 UTF-8 문자열을 저장할 수 있는 자료형을 추가했다.
2010년 3월 24일에 utf8mb4 라는 charset을 추가하였다. (MYSQL 5.5.3 에 추가됨)
(관련 : https://dev.mysql.com/doc/relnotes/mysql/5.5/en/news-5-5-3.html )

> 한글 해석 : utf8mb4 가 추가되었습니다. 이것은 utf8 과 비슷하지만 확장된 문자를 지원하기 위해서 4바이트까지 저장할 수 있습니다.
더 자세한 이론을 원하면 Wikipedia 의 Plane 항목을 읽어보길 바란다.
(어려움. 그냥 쓰윽 읽어보세요. http://en.wikipedia.org/wiki/Plane_(Unicode) )
대충 이런 뜻이다.
- utf8 : Basic Plane.
- utf8mb4 : Basic Plane + Supplementary Plane.
그리고 중요한 것!!! Emoji 문자열이 모두 4 Byte 이다!!
요즘 스마트폰에서 이미 있는 문자이고, 라엘이의 경우 운영체제로 Mac OS X 를 사용하는데,
Mac 에서 커멘드+컨트롤+스페이스를 입력하면 나오는 키보드이다.
-- 참고 이미지 --
-- 참고 이미지 --
즉 이러한 SMP (Supplementary Multilingual Plane) 를 처리하기 위해서
당신의 DBMS 가 utf8mb4 를 지원한다면 반드시 이것으로 지정하길 바란다.
Collation (정렬 방식).
latin1 (2바이트), utf8 (가변3바이트), utf8mb4 (가변4바이트)는 저장공간의 크기이다.
위의 것들은 charset 이라고 부른다.
(웹)프로그램과 데이터베이스가 문자를 주고 받을 때는 charset 만 설정하면 된다.
“내가 보낼 문자열은 utf8mb4 에요!” 라고 알려주고 text stream 을 전송하면 알맞게 처리하기 때문이다.
Collation 은 텍스트 데이터를 정렬(ORDER BY)할 때 사용한다. 즉 text 계열 자료형에서만 사용할 수 있는 속성이다.
int 형 : 1500 < 1700 으로 명확하다.
date 형 : 2013-10-20 < 2015-12-20 으로 명확하다.
- 그렇다면 text 형 :
a 와 b 중 어느 것이 더 큰가?
a 와 A 중 어느 것이 더 큰가?
a 와 á 중 어느 것이 더 큰가?
- 주로 많이 사용하는 collation 3가지 비교.
ORDER BY `text` ASC
* utf8_bin (or utf8mb4_bin)
바이너리 저장 값 그대로 정렬한다.
hex 코드(16진수)로 A 는 41, B 는 42, a 는 61, b 는 62 이기 때문에 다음 순서로 출력된다.

* utf8_general_ci (or utf8mb4_general_ci)
텍스트 정렬할 때 a 다음에 b 가 나타나야 한다는 생각으로 나온 정렬방식. 일반적으로 널리 사용된다.
라틴계열 문자를 사람의 인식에 맞게 정렬한다.
바이너리를 한번 가공한 것이다.

* utf8_unicode_ci (or utf8mb4_unicode_ci)
general_ci 보다 조금 더 사람에 맞게 정렬한다.
한국어, 영어, 중국어, 일본어 사용환경에서는 general_ci 와 unicode_ci 의 결과가 동일하다.
뭔가 더 특수한 문자의 정렬 순서가 변경된다. 다음의 스크린샷을 참조하여라.
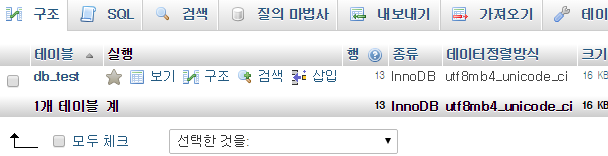
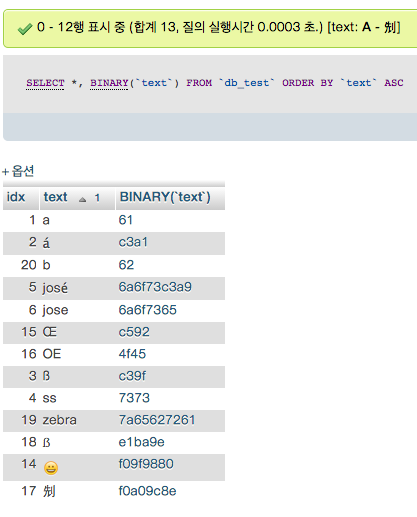
<위의 예시는 상당히 많은 의미를 가지고 있다. 자세히 살펴보도록 하자.>
다음은 권장하는 charset 과 collation 설정 값이다.
1) MySQL 5.5.3 이전 = utf8 charset 에, utf8_general_ci collation 사용.
2) MySQL 이 최신일 때 = utf8mb4 charset 에, utf8mb4_unicode_ci collation 사용.
요약 : 이 문제는 MYSQL / MariaDB 에서만 일어납니다.
1) 다국어를 처리할 수 있는 UTF-8 이라는 저장방식이 있음. 원래 설계는 가변4바이트임.
2) 전세계 모든 언어문자를 다 카운트 해봤는데 3 바이트가 안됨.
3) MYSQL/MariaDB 에서는 공간절약+속도향상 을 위해서 utf8 을 가변3바이트로 설계함.
4) Emoji 같은 새로나온 문자가 UTF-8의 남은 영역을 사용하려함 (4바이트 영역).
5) MYSQL/MariaDB 에서 가변4바이트 자료형인 utf8mb4 를 추가함. (2010년 3월에).
기존 utf8 시스템을 utf8mb4 로 바꾸어도 값의 손실은 없습니다.
Emoji 문자열의 저장을 지원하지 않으려면 굳이 utf8mb4 를 사용하지 않아도 됩니다. (이 경우 데이터베이스에 텍스트 값 저장 전에 필터링을 하기 바랍니다.)
'DB > MySQL|MariaDB' 카테고리의 다른 글
| [에러] Packet for query is too large!!! (0) | 2017.09.25 |
|---|---|
| [퍼옴] MySQL Index - 기본 (0) | 2017.09.08 |
| Mysql 외래키 간단히 정리 (0) | 2017.07.05 |
| MySQL DISTINCT의 특징! (0) | 2017.04.21 |
| MyISAM & InnoDB차이 (0) | 2017.03.28 |
- ML
- memory
- BigData
- spark
- Configuration
- 중앙정보처리학원
- Java
- serverless
- javascript
- 텐서플로우
- 모두의딥러닝
- python
- spring
- mybatis
- 파이썬
- TDD
- Docker
- Error
- 머신러닝
- NIO
- AI
- 점프투파이썬
- Gradle
- tensorflow
- API
- AWS
- web
- executor
- Maven
- mysql
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |